Broadly speaking, on a MyISAM Table with a range scan, the process is:
- Find the first Index result using the
BTREE (inside the .MYI file) and access the row result (on the .MYD file) - Handler_read_key
- Get the next result, using the index (and in the same order), until the value retrieved is larger than the one defined (multiple instances of
Handler_read_next)
You can actually get this plan by observing that you get a range join type on EXPLAIN and on the Handler_* counters on SHOW SESSION STATUS.
Theoretically, the first step is O(log n) -where n is the number of records indexed (the table size)- while the second is O(m)- where m is the number of records returned. So, theoretically, a larger table will take more to return the records. Why so I say theorically? Because the O() notation can be deceitful if you do not have into account the constants. Indexes usually end up in memory, while rows (specially on MyISAM, which has not a dedicated buffer for data) can be on disk, so the difference in performance of both operations is large. Also, MyISAM has problems with large tables, so then number of levels tend not to be too large.
Let me show you an unrelated graph:
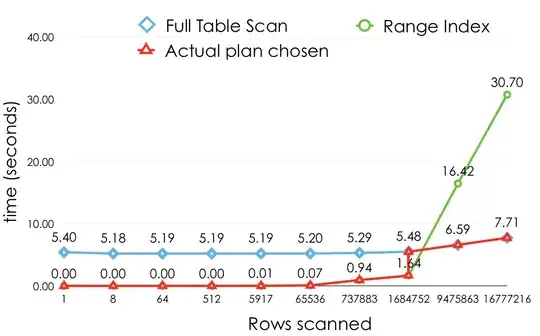
In the above graph, the full table scan (blue line) should be flat, because all rows are examined, but it is not mainly because at that point, reading and returning 16M rows is more costly than returning only 1.
So the answer is- both operations take time, which one dominates depend on the actual value of m and n, plus the state of the database in terms of speed of hardware (memory, disk) and the state of the buffers (filesystem, key buffer). In conventional usage, an index scan of a single row is a very fast operation, but it depends comparing to what, and if you have into account extreme cases, like large tables where the BTREE index doesn't fit into memory.