See this question here: Database Administrators meta
My knowledge of databases and SQL is based in most on university classes. Anyhow, I spent few monts (almost a year) in a company, where I was working with databases.
I have read few books and I have taken part in few trainings about databases such as MySQL, PostgreSQL, SQLite, Oracle and also few nonSQL dbs such us MongoDB, Redis, ElasticSearch etc.
As well as I said, I am begginer, with a lot of lacks of knowledge but today, someone told something, what is totally against my begginer's knowledge.
Let me explain. Let's take SQL database and create simple table Person with few records inside:
id | name | age
-----------------
1 | Alex | 24
2 | Brad | 34
3 | Chris | 29
4 | David | 28
5 | Eric | 18
6 | Fred | 42
7 | Greg | 65
8 | Hubert | 53
9 | Irvin | 17
10 | John | 19
11 | Karl | 23
Now, it's the part, I would like to focus on - id is the INDEX.
So far, I thought it works in this way: when a table is being created the INDEX is empty. When I am adding new record to my table the INDEX is being recalculated based on some alghortims. For example:
Grouping one by one:
1 ... N
N+1 ... 2N
...
XN+1 ... (X+1)N
so, for my example with size = 11 elements and N = 3 it will be like this:
id | name | age
-----------------
1 | Alex | 24 // group0
2 | Brad | 34 // group0
3 | Chris | 29 // group0
4 | David | 28 // group1
5 | Eric | 18 // group1
6 | Fred | 42 // group1
7 | Greg | 65 // group2
8 | Hubert | 53 // group2
9 | Irvin | 17 // group2
10 | John | 19 // group3
11 | Karl | 23 // group3
So, when I am using query SELECT * FROM Person WHERE id = 8 it will do some simple calculation 8 / 3 = 2, so we have to look for this object in group2 and then this row will be returned:
8 | Hubert | 53
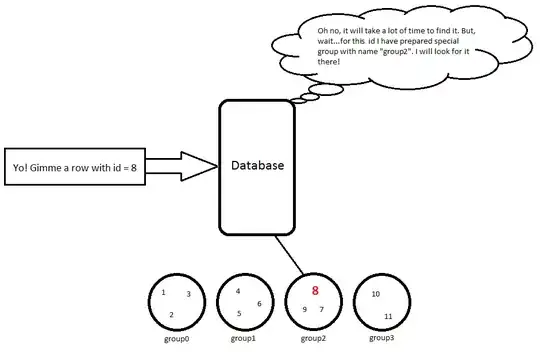
This approach works in time O(k) where k << size. Of course, an alghoritm to organise rows in groups is for sure much more complicated but I think this simple example shows my point of view.
So now, I would like to present another approach, which has been showed me today.
Let's take once again this table:
id | name | age
-----------------
1 | Alex | 24
2 | Brad | 34
3 | Chris | 29
4 | David | 28
5 | Eric | 18
6 | Fred | 42
7 | Greg | 65
8 | Hubert | 53
9 | Irvin | 17
10 | John | 19
11 | Karl | 23
Now, we are creating something similar to Hashmap(in fact, literally it is a Hash Map) which maps id to address of row with this id. Let's say:
id | addr
---------
1 | @0001
2 | @0010
3 | @0011
4 | @0100
5 | @0101
6 | @0110
7 | @0111
8 | @1000
9 | @1001
10 | @1010
11 | @1011
So now, when I am running my query: SELECT * FROM Person WHERE id = 8
it will map directly id = 8 to address in memory and the row will be returned. Of course complexity of this is O(1).
So now, I have got few questions.
1. What are the adventages and disadventages of both solutions?
2. Which one is more popular in current database implementations? Maybe different dbs use different approaches?
3. Does it exist in nonSQL dbs?
Thank you in advance
Clustered Indexeswhich are different from normal indexes on columns that areNon Clustered Indexes– Vladimir Oselsky Apr 04 '14 at 14:50