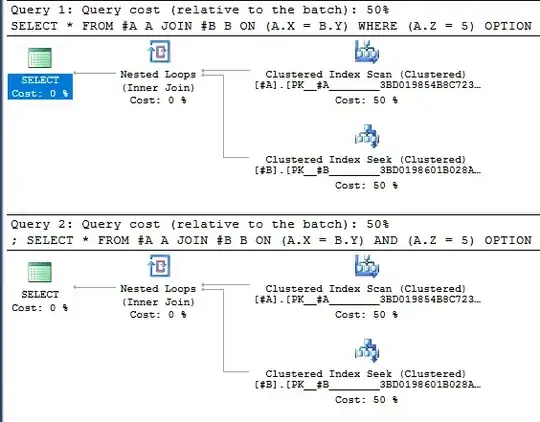
The best way is the one that matches your team's coding style. If you work alone then the best way is the one that you find to be the most readable. There is currently no performance difference for the queries in the question.
You can use the undocumented trace flag 8606 to see this for yourself. Here's the code that I'm testing with:
CREATE TABLE #A (X INT NOT NULL, Z INT NOT NULL, PRIMARY KEY (X));
CREATE TABLE #B (Y INT NOT NULL, Z INT NOT NULL, PRIMARY KEY (Y));
SELECT *
FROM #A A
JOIN #B B ON (A.X = B.Y)
WHERE (A.Z = 5)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606);
SELECT *
FROM #A A
JOIN #B B ON (A.X = B.Y) AND (A.Z = 5)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606);
Not only do the queries have the exact same plan:
They also have the same internal input tree:
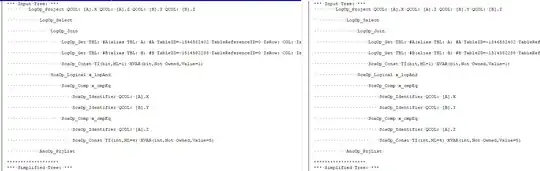
In other words, SQL Server rewrites the queries to be the same before optimization occurs. Therefore, there will not be a performance difference.

