Does query optimizer manage to prioritize the first clause, avoiding
to do the subquery if the simpler clause is true for at least 1 record.
It can do
create table customers(id int identity primary key, firstname varchar(10)) ;
insert into customers values ('John'), ('Johnathan'), ('George');
create table customer_emails(id_customer int, email varchar(100));
insert into customer_emails values (1, 'John@example.com'), (2, 'Johnathan@example.com');
In the plan I got the first row matched the LIKE 'John%' predicate and the scan against customer_emails was not executed at all.
However your question is phrased as
if the simpler clause is true for at least 1 record
That would imply that the simpler WHERE clause is evaluated in its entirety and only if that fails is the second one evaluated.
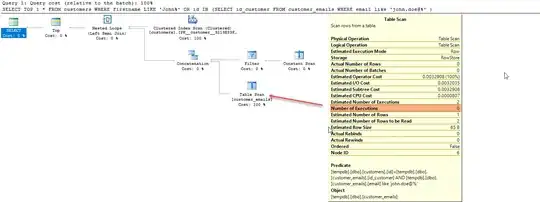
For
SELECT TOP 1 *
FROM customers
WHERE firstname LIKE 'George%'
OR id IN (SELECT id_customer
FROM customer_emails
WHERE email like 'George.doe@%' );
Three rows were processed before one was found matching LIKE 'George%'and there were two ensuing scans on customer_emails
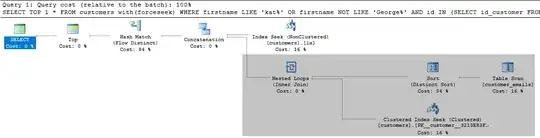
Rewriting as follows...
create index ix on customers(firstname) include(id)
SELECT TOP 1 *
FROM customers with(forceseek)
WHERE firstname LIKE 'George%'
OR firstname NOT LIKE 'George%' AND id IN (SELECT id_customer
FROM customer_emails
WHERE email like 'George.doe@%' );
... happens to give a plan where the operators in the shaded area for the IN part don't get executed if the simpler predicate returns a row but this plan isn't guaranteed.