I'm fitting a psychometric function to a range of data. The majority of this data lends itself to a sigmoidal fit (i.e. participants can do the task), but some individuals are absolutely unable to do the task. I'm planning to compare the slopes obtained from different conditions, but I've hit a wall with the unable-to-do-the-task data.
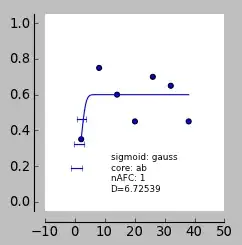
Fitting a function to this data, the slope should be nearly flat, right? However, the data is really noisy and some weird fitting is occurring - I end up getting erroneously high slopes. I'm using pypsignifit, the parameters I'm using can be seen below. Any idea how to stop this happening?
num_of_block = 7
num_of_trials = 20
stimulus_intensities=[3, 7, 13, 20, 27, 32, 39] # stimulus levels
percent_correct=[.38, .75, .6, .43, .7, .65, .43] # percent correct sessions 1-3
num_observations = [num_of_trials] * num_of_block # observations per block
data= np.c_[stimulus_intensities, percent_correct, num_observations]
nafc = 1
constraints = ('unconstrained', 'unconstrained', 'unconstrained', 'Beta(2,20)' )
boot = psi.BootstrapInference ( data, core='ab', sigmoid='gauss', priors=constraints, nafc=nafc )
boot.sample(2000)
print 'pse', boot.getThres(0.5)
print 'slope', boot.getSlope()
print 'jnd', (boot.getThres(0.75)-boot.getThres(0.25))