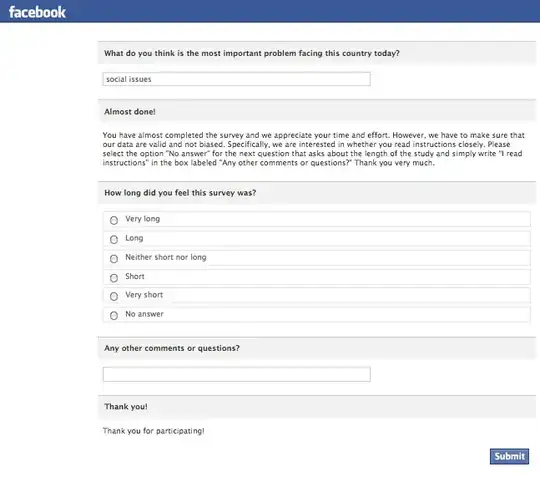
I have an experimental study with a list of demographic and related questions and in order to identify data from participants that were potentially just answering the questions at random (to get through them more quickly I would assume), I've included two very similar 7-point likert scale questions at different points in the survey. My assumption would be that since the questions are reflective, the answers participants should give will be at least somewhat similar between the two questions (eg, it should be very unlikely that a participant answers 7 to one question yet 1 to the other).
I haven't yet collected the data, however I would like to have a method for determining which sets of data are suspicious (might be considered for exclusion in analysis) based on these control questions. One method might be to simply determine where the data fit on a Gaussian distribution. However, I think that the limited discriminating power of a 7-point scale would make this an improper test. My other idea was to do a cluster analysis on the data, looking for five groups: three along the line of correlation (between the questions), and two to examine unusually high/low and low/high values. I thought this could provide better suggestions for which data sets might be unusual since it wouldn't use somewhat arbitrary comparisons, it would only use the data given.
I'd really appreciate any suggestions for a better method, or improvements I could make as well as any comments toward more "standard" practices in this area, since I'm somewhat new to research.